Self-Attention Generative Adversarial Networks는 기존 convolution layer의 한계를 극복하고자 attention 개념을 GAN에 처음으로 적용한 논문입니다.
https://arxiv.org/abs/1805.08318
Convolution layer의 한계
GAN, CNN 등의 기존 네트워크들은 보통 convolution layer 기반입니다. 이러한 convolution 기반 네트워크들은 class가 많은 데이터셋(ex. ImageNet) I의 generator 모델을 학습할때, 특정 class의 이미지를 잘 생성하지 못한다는 단점이 있습니다. 바다나 하늘같은 풍경들은 잘 생성해내지만, 동물들 같은 texture가 많은 이미지들을 잘 생성하지 못했습니다.
이러한 이유에 대해 저자는 convolution 연산이 kernerl 기반으로 local한 영역에 대한 행해지기 때문에, 멀리 떨어져 있는 point의 관계를 학습하지 못한다고 합니다.
(1,1)와 (10,10)간의 관계를 보기 위해선 convolution layer를 여러번 통과한 뒤에야 서로의 관계를 학습할 수 있습니다. 이를 위해 kernerl size를 크게 만들 수 있지만, 이렇게 kernerl size를 키우게 되면, 연산의 효율성을 떨어트리고 모델이 무거워진다는 단점이 존재합니다.
이러한 한계가 존재하는 convolution 기반 학습 대신 이 논문에서는 attention 개념을 도입하여, 연산의 효율성을 유지한채 멀리 떨어진 곳들의 관계(long-range dependency)도 학습할 수 있도록 하였습니다.
Self-Attention Network
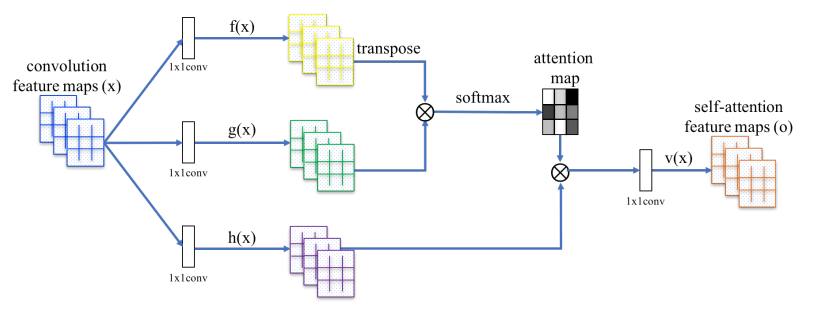
위의 figure는 SAGAN의 네트워크입니다. 맨 왼쪽 x는 convolution 연산 결과 나온 중간 feature map이고 이를 1x1 convolution layer를 통과시켜 f(x), g(x), h(x)로 세가지의 map을 만듭니다.

그 뒤, 위의 식처럼 f(x)^T와 g(x)의 matrix multiplication 계산 후 softmax를 취해줍니다. 이렇게 계산된 베타는 j번째 영역을 만들때 i번째의 위치가 얼만큼 관여하는지에 대한 것을 나타냅니다. 즉, weight과 같은 개념입니다.

그리고 h(x)와의 곱을 통해 최종 o_j가 도출되는데, 이 o_j는 j번째 영역이 이미지 전체를 구성하는데 얼마만큼 영향이 가는 부분인지에 대한 값입니다. 즉, self-attention feature maps에 해당하는 것입니다.

그리고 마지막으로 도출된 o_j와 x_i를 더해줘 최종적으로 y_i를 계산합니다. 학습 초반에는 감마를 0으로 두어 convolution 결과만 가지고 local 부분에 대해 학습을 진행하고, 점차적으로 감마의 값을 높혀 attention 개념을 더 많이 학습하도록 전략을 짭니다. Generator, Discriminator 둘다 모두 attention을 적용하였습니다.
Training Techniques
GAN의 학습을 보다 안정적으로 진행시키기 위해 두가지의 학습전략을 저자는 사용합니다.
1. Spectral Normalization
기존에 discriminator에 적용되던 spectral normalization을 generator에도 적용하여 학습이 튀는 현상을 방지하고 계산량도 줄어 더 효율적이라고 합니다.
2. Two-Timescale Update Rule (TTUR)
일반적으로 GAN 학습시 discriminator의 학습이 generator보다 훨씬 느리게 학습이 됩니다. 그렇다보니 학습의 balance를 맞추기 위해 discriminator를 5번 학습하고 generator를 학습하는 등 여러가지 학습전략이 존재했습니다. 저자는 여러번 학습하지 않고 단순히, dicriminator와 generator의 learning rate를 서로 다르게 설정하여 한번에 학습을 하되 discrimator 학습이 빠르게 할 수 있도록 하였습니다.
Experiment Results

위 figure는 generator의 마지막 layer의 attention map을 뽑은 것으로, 이미지 위의 red, green, blue를 생성하는데 가장 영향을 많이 미친 영역을 보여줍니다. 해당 포인트를 만드는데 있어서 그 포인트와 비슷한 색상, 질감을 가진 포인트가 가장 많은 영향을 끼치도록 학습이 진행됨을 확인 할 수 있습니다.

위의 figure를 보면 다양한 상황의 다양한 이미지들이 이질감 없이 자연스럽게 생성된 것을 확인 할 수 있습니다.




댓글