Image Style Transfer Using Convolutional Neural Networks는 Image에서의 Style를 변화시킨 최초의 논문으로 이 논문을 기점으로 다양한 style transfer 논문들이 나오게 됩니다.
Content + Style
Style transfer란 하나의 이미지를 내가 원하는 다른 이미지처럼 변형시켜주는 것입니다.

즉, 위의 figure처럼 input image(강가의 집)의 content는 그대로 둔 채 다른 image의 style(고흐의 별이 빛나는 밤)을 가져와서 입혀주는 것입니다.
저자는 convolution neural network인 VGG-19를 이용하여 style transfer를 진행하였습니다. 특이한 점은 네트워크의 weight를 업데이트하며 학습하는 기존의 CNN 학습과는 다르게 네트워크 자체를 업데이트하지 않는다는 점입니다.

위 figure는 저자가 사용한 style transfer 알고리즘입니다. 총 네트워크에 들어가는 input image는 3개로 먼저 가장 오른쪽 p는 content image이고 가장 왼쪽의 a는 style image입니다. 그리고 가운데의 x는 random white noise로 이 noise 이미지가 최종적으로 학습을 통해 산출되는 content에 style이 입혀진 최종 결과 이미지가 됩니다. figure 중간의 Conv block들은 VGG-19 네트워크로서, 미리 Imagenet으로 pre-trained된 네트워크입니다.
이 논문의 학습전략은 미리 학습이 완료된 네트워크에 이미지를 넣어 중간 feature들을 뽑고, 이 feature를 활용해 loss 계산을 한 뒤, random white noise 이미지의 pixel 값을 업데이트해주는 것입니다. 앞서 언급했듯이 네트워크를 업데이트하는 것이 아닌 input 이미지의 pixel 값을 업데이트하는 것이 특징입니다.
Image representations
저자는 content image에서는 content를 활용하고 style image에서는 style만 활용할 수 있도록 학습전략을 구축합니다.
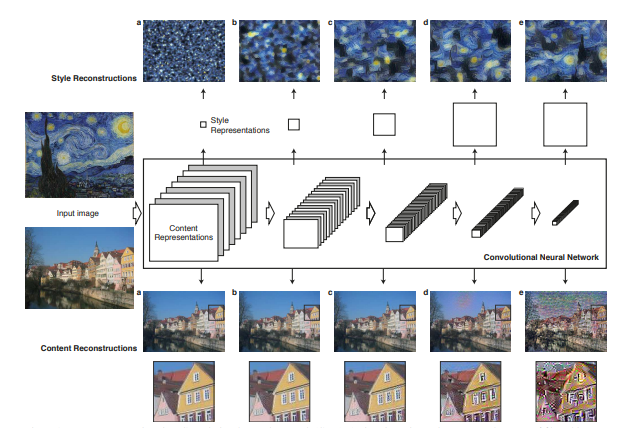
위 figure는 pre-trained VGG 네트워크의 중간 feature들입니다. 왼쪽이 network의 초기 layer에서 추출된 low feature들이고 오른쪽으로 갈수록 깊어진 layer에서 추출된 high feature들입니다.
1. Content representation
먼저 아래쪽의 content 이미지의 low feature들을 보면 input 이미지와 비슷한것을 볼 수 있습니다. 반면에 오른쪽의 high feature들을 보면 pixel 수준의 정보들은 뭉개져서 사라지지만, 이미지의 실질적인 content 정보들만 남아있는 상태임을 확인 할 수 있습니다. 저자는 content 이미지의 이 high feature를 활용하여 학습을 진행합니다.
2. Style representation
위쪽의 style 이미지를 가지고는 공간적 정보가 없는 style 정보를 추출하기 위해, 직접적인 layer의 feature를 뽑는 것이 아니고 feature간의 상관관계를 계산하는 Gram matrix를 통해 추출합니다.

content와는 다르게 style feature는 단일 layer에서 뽑히는 feature의 계산이 아닌 각 층에서 뽑히는 첫번째 feature들간의 상관관계를 계산합니다. a는 conv1_1만의 결과이고 b는 conv1_1과 conv2_1의 결과, c는 conv1_1, conv2_1, conv3_1의 결과, d는 conv1_1, ..., conv4_1의 결과, e는 conv1_1, ..., conv5_1의 결과이다. 깊은 layer들을 포함할수록 이미지의 styel을 대략적으로 대변하고 있는 것을 볼 수 있습니다.
Loss Function
loss function은 content feature와 style feature의 계산에서 생기는 두가지 loss의 합으로 구성됩니다.

먼저 content loss는 4번째 conv layer에서 추출된 feture들 간의 L2 norm을 통해 계산됩니다.

Style loss는 각 층에서 추출된 feature들간의 Gram matrix을 계산하고 계산된 값들의 L2 통해 계산됩니다.
최종 loss는 아래와 같이 content loss와 style loss의 weight sum을 통해 계산됩니다.

그리고 이 loss를 통해 네트워크가 아닌 random white noise의 pxiel 값들이 업데이트됩니다.

Result

위 이미지는 content loss(알파)와 style loss(베타)의 weight 비율에 따른 결과 이미지들입니다. style loss를 더 강조할수록 content는 망가지고 추상적인 style만 남은 이미지가 되가는 것을 볼 수 있습니다.
이처럼 적적한 weight를 통해 결과 이미지를 생성할 수 있습니다.
아래는 논문에서 제공하는 동일한 content 이미지에 다양한 style을 입힌 결과 이미지들입니다.





댓글